How to Import Large Collections
Learn to efficiently process hundreds or thousands of items using guided workflows for file upload, data mapping, and quality control during large-scale digitization projects.
Planning Your Import Strategy
Successful bulk imports start with good preparation. The tabbed workflow guides you through data upload, preview, field mapping, and processing - but understanding your data structure and mapping strategy beforehand saves time and prevents errors during the import process.
🎯 Before You Start
Review your data: Understand the structure and quality of your source data (CSV, JSON, or CONTENTdm collection)
Plan field mappings: Identify which source fields correspond to Archeum's standard fields (title, description, etc.)
Prepare for custom fields: Note any specialized metadata that will need custom field mappings
Test with small batches: Consider running a small test import first to verify your mapping strategy
📁 File Upload Path
Best for CSV exports from databases, spreadsheets, or other digital collection systems where you have local files.
🔗 CONTENTdm Integration
Perfect for migrating from CONTENTdm servers - fetches data directly without requiring file exports.
🎨 Visual Mapping
Drag-and-drop interface ensures your source data fields align correctly with Archeum's schema.
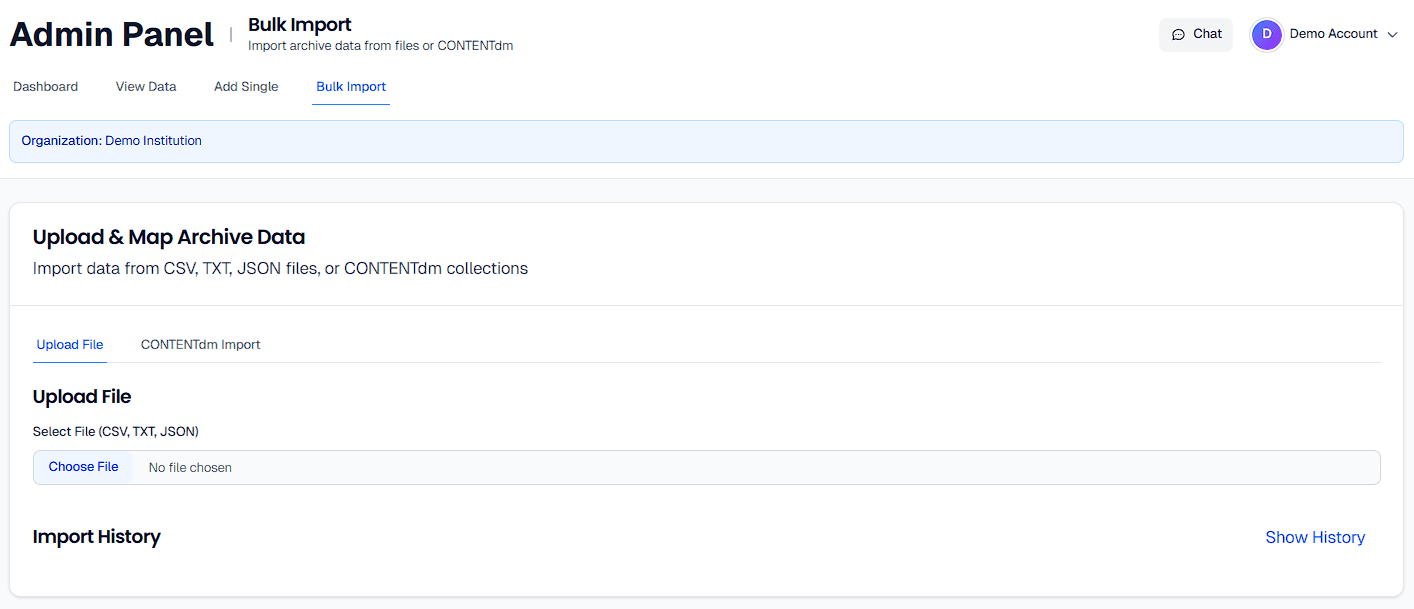
Starting with File Upload
Preparing Your Data Files
Before uploading, ensure your data files are properly formatted and complete. The system processes your file immediately upon selection, so having clean, well-structured data from the start prevents issues during mapping and import.
📊 File Format Guidelines
CSV files: Ensure consistent column headers, escape commas in text fields, and use UTF-8 encoding for special characters
TXT files: Use consistent delimiters (tabs or pipes work well), avoid the delimiter character within field content
JSON files: Structure as an array of objects, ensure all objects have consistent property names
All formats: Include column/field headers, avoid completely empty rows, and check for data consistency
⚡ What Happens After Upload
• System immediately processes and validates your file structure
• Counts total items and generates a preview of the first few records
• Automatically switches to the Preview Data tab to show you what was loaded
• Resets any previous mapping settings to start fresh with your new data
✅ Success Feedback
When a file is successfully loaded, you'll see a confirmation message showing the file name, total item count, and automatic navigation to the Preview Data tab.
CONTENTdm Import Tab
CONTENTdm Integration
The CONTENTdm Import tab provides direct integration with CONTENTdm servers. Enter your server URL and collection alias to fetch data directly into the preview system.
Required Fields
- • CONTENTdm Server URL: Full server URL
- • Collection Alias: Short collection identifier
Fetch Process
- • Real-time progress indicator during fetch
- • Cancel button to stop fetching
- • Error reporting for connection issues
- • Automatic switch to Preview Data when complete
🔗 Direct Integration
CONTENTdm data is fetched directly from the server and processed the same way as uploaded files. The system automatically clears any previously loaded file data when CONTENTdm data is fetched.
Preview Data Tab
Data Preview
The Preview Data tab shows a sample of your uploaded data in a table format. It displays the first few rows/items to help you verify the data structure before mapping.
📋 Preview Features
- • Shows first 5 rows for CSV/TXT files, first 3 items for JSON
- • Displays all column headers dynamically
- • Truncates long values (>50 characters) with "..." indicator
- • Shows total item count for the entire file
- • Scrollable table for files with many columns
Visual Field Mapping Tab
Field Mapping Interface
The Field Mapping tab uses the VisualFieldMapper component to provide a drag-and-drop interface for mapping source fields to target Archeum fields. This tab only appears when preview data is available.
Mapping Features
- • Drag-and-drop field assignment
- • Visual validation indicators (✓ or ⚠)
- • Sample value preview for each field
- • Required field highlighting
- • Real-time mapping validation
Validation System
- • Checks for required field mappings
- • Updates tab indicator (✓ valid, ⚠ issues)
- • Prevents import if mappings invalid
- • Shows missing required fields list
- • Disabled state during import process
Import Actions
Import Process
Once field mapping is complete and valid, the Import Actions section provides controls for starting the import process, monitoring progress, and handling errors.
Import Progress Tracking
- • Real-time progress bar with current/total item counts
- • Success metrics: imported, updated, skipped counts
- • Error tracking with detailed error messages
- • Completion status with final statistics
Import Controls
- • Start Import button (disabled until mapping valid)
- • Cancel Import button during processing
- • Import state management and navigation prevention
- • Validation warnings for missing required fields
🔄 Background Processing
The import process runs with AI embedding generation, creating searchable vector representations for each item. Large imports are processed efficiently with progress feedback and error recovery.
Import History
Import History Section
The Import History section provides a collapsible view of all past import jobs with their status, progress, and detailed job information accessible through modals.
History Features
- • Collapsible section with "Show/Hide History" toggle
- • Tabular view with Date, Status, Progress, Actions columns
- • Status badges (Completed, Failed, In Progress)
- • Progress indicators showing processed/total items
- • "View Details" buttons for each job
Job Status Types
- • COMPLETED - Successfully finished
- • FAILED - Import failed
- • IN_PROGRESS - Currently processing
- • Loading states with spinner animation
- • Empty state message when no history exists
📋 Job Details Modal
Clicking "View Details" opens the ImportJobModal component with comprehensive job information including error details, processing statistics, and individual item status.
Technical Implementation
System Components
The bulk import system uses several specialized hooks and components to handle the complex workflow of data processing, field mapping, and background import jobs.
Core Hooks
- •
useContentDMFetch- CONTENTdm server integration - •
useBulkImport- Import progress tracking - •
parseDelimitedFile- CSV/TXT processing - • Background job management and status monitoring
UI Components
- • Tabbed interface with dynamic tab visibility
- • VisualFieldMapper for drag-and-drop mapping
- • ImportJobModal for detailed job information
- • Real-time progress indicators and validation
🔧 Processing Features
The system includes AI embedding generation, background processing with cancellation support, error recovery mechanisms, and navigation prevention during active imports.